Software Rendering 3: Textures and more colours In our previous episode, we managed to render our first triangle, and I promised that in this episode, we'll get into texturing, more complex shapes, Z-Buffering and all that fine stuff. So naturally, I'm here to deliver on that promise.... at least, partially. Today, we'll be discussing textures, which are an integral part of any graphical applications. https://read.cash/@Metalhead33/software-rendering-2-pipelines-and-triangles-f4379638 Textured Rectangle Remember our trusty little texture class? Well, we can use it for more than just framebuffers. But to make our work easier, we should add a convenience function to the Texture class.
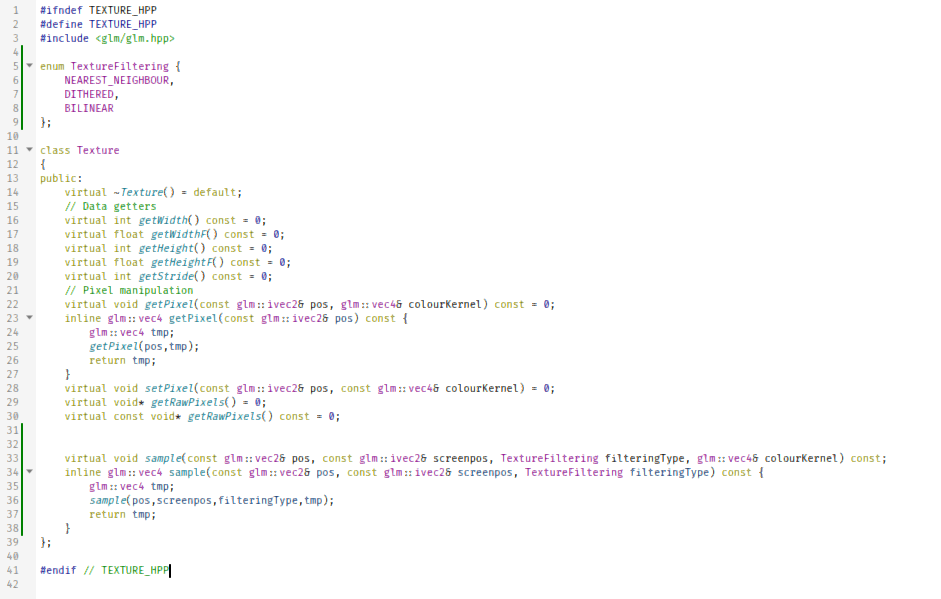
#ifndef TEXTURE_HPP #define TEXTURE_HPP #include <glm/glm.hpp> enum TextureFiltering { NEAREST_NEIGHBOUR, DITHERED, BILINEAR }; class Texture { public: virtual ~Texture() = default; // Data getters virtual int getWidth() const = 0; virtual float getWidthF() const = 0; virtual int getHeight() const = 0; virtual float getHeightF() const = 0; virtual int getStride() const = 0; // Pixel manipulation virtual void getPixel(const glm::ivec2& pos, glm::vec4& colourKernel) const = 0; inline glm::vec4 getPixel(const glm::ivec2& pos) const { glm::vec4 tmp; getPixel(pos,tmp); return tmp; } virtual void setPixel(const glm::ivec2& pos, const glm::vec4& colourKernel) = 0; virtual void* getRawPixels() = 0; virtual const void* getRawPixels() const = 0; virtual void sample(const glm::vec2& pos, const glm::ivec2& screenpos, TextureFiltering filteringType, glm::vec4& colourKernel) const; inline glm::vec4 sample(const glm::vec2& pos, const glm::ivec2& screenpos, TextureFiltering filteringType) const { glm::vec4 tmp; sample(pos,screenpos,filteringType,tmp); return tmp; } }; #endif // TEXTURE_HPP
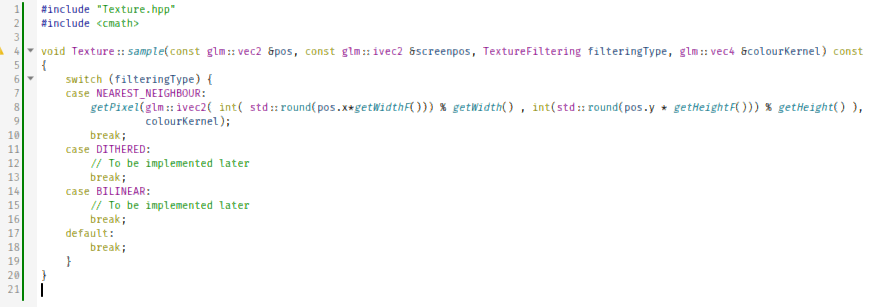
#include "Texture.hpp" #include <cmath> void Texture::sample(const glm::vec2 &pos, const glm::ivec2 &screenpos, TextureFiltering filteringType, glm::vec4 &colourKernel) const { switch (filteringType) { case NEAREST_NEIGHBOUR: getPixel(glm::ivec2( int( std::round(pos.x*getWidthF())) % getWidth() , int(std::round(pos.y * getHeightF())) % getHeight() ), colourKernel); break; case DITHERED: // To be implemented later break; case BILINEAR: // To be implemented later break; default: break; } } So, what are those three types of texture filtering, and why do we need to have a screen position as an argument for sampling a texture?!

**Nearest-Neighbour filtering** simply multiplies the normalized texture coordinate with the texture's dimensions and rounds it to an integer. E.g. in case of a 128x128 texture, the normalized texture coordinate `{ 0.533, 0.73 }` is first translated to `{ 68.224, 93.44 }`, then rounded to the integers `{ 68, 93 }`. This results in the infamous crispy pixelated look. Recommended for pixel art, but looks horrible on textures that are intended to be photorealistic. This is the simplest type of texture-filtering to implement. **Bilinear filtering** takes a weighted average of the colour value of four pixels. In case of a 128x128 texture, for the normalized texture coordinate `{ 0.533, 0.73 }` - which gets translated to `{ 68.224, 93.44 }` -, that would mean taking a weighted average of the colour values of `{ 68, 93 }`, `{ 69, 93 }`, `{ 68, 94 }` and `{ 69, 94 }` respectively, but we'll get into the details of the algorithm later. The point is, that this type of texture filtering results in a smooth - and blurry, if texture resolution is low - look. Good for photorealistic textures, bad for pixel art. **Dithered** is basically a type of pseudo-bilinear filtering. It fakes bilinear filtering by employing ordered dithering. This results in a noticeable checkerboard pattern if you look too closely, but is indistinguishable from real bilinear filtering if you are far enough from the monitor. For dithered texture filtering, we'll also need some kind of input to manipulate the dither pattern, and the screen position is the most ideal for that. https://en.wikipedia.org/wiki/Ordered_dithering For now, we'll be content with **nearest-neighbour** filtering, but we will implement the other two algorithms down the line. Okay, but we'll need to import a texture! For this purpose, I recommend using stb. But first, need to adjust our StandardTexture interface to accomodate it for pre-existing pixel data. https://github.com/nothings/stb
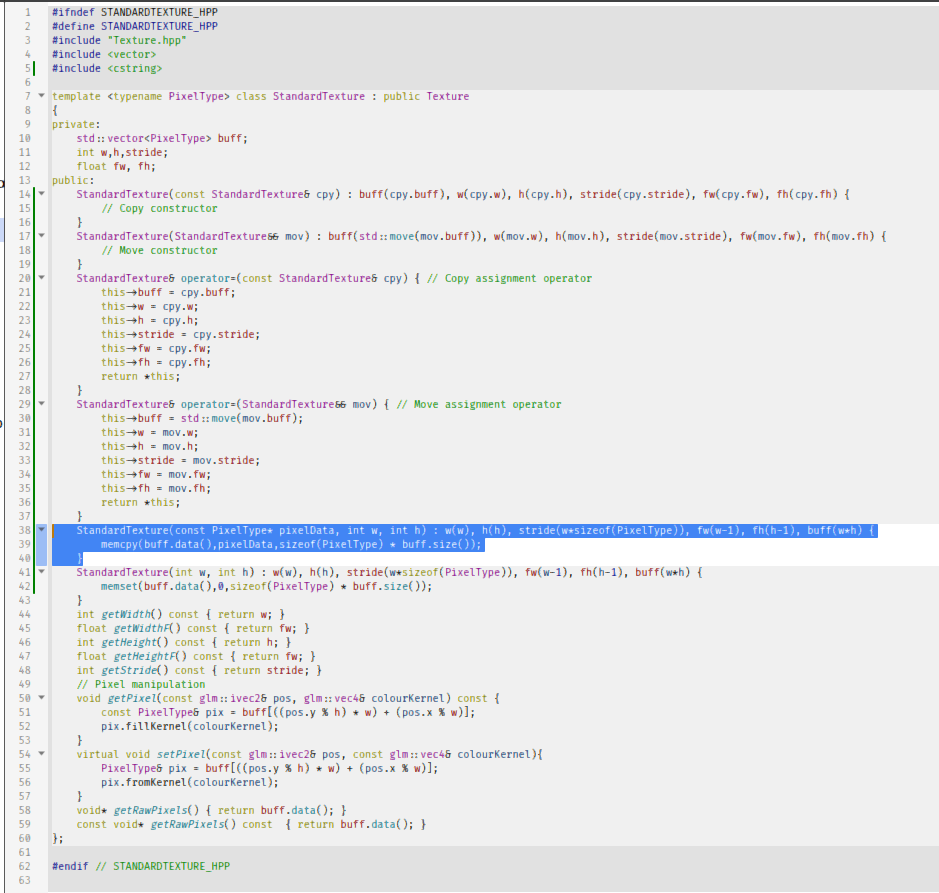
#ifndef STANDARDTEXTURE_HPP #define STANDARDTEXTURE_HPP #include "Texture.hpp" #include <vector> #include <cstring> template <typename PixelType> class StandardTexture : public Texture { private: std::vector<PixelType> buff; int w,h,stride; float fw, fh; public: StandardTexture(const StandardTexture& cpy) : buff(cpy.buff), w(cpy.w), h(cpy.h), stride(cpy.stride), fw(cpy.fw), fh(cpy.fh) { // Copy constructor } StandardTexture(StandardTexture&& mov) : buff(std::move(mov.buff)), w(mov.w), h(mov.h), stride(mov.stride), fw(mov.fw), fh(mov.fh) { // Move constructor } StandardTexture& operator=(const StandardTexture& cpy) { // Copy assignment operator this->buff = cpy.buff; this->w = cpy.w; this->h = cpy.h; this->stride = cpy.stride; this->fw = cpy.fw; this->fh = cpy.fh; return *this; } StandardTexture& operator=(StandardTexture&& mov) { // Move assignment operator this->buff = std::move(mov.buff); this->w = mov.w; this->h = mov.h; this->stride = mov.stride; this->fw = mov.fw; this->fh = mov.fh; return *this; } StandardTexture(const PixelType* pixelData, int w, int h) : w(w), h(h), stride(w*sizeof(PixelType)), fw(w-1), fh(h-1), buff(w*h) { memcpy(buff.data(),pixelData,sizeof(PixelType) * buff.size()); } StandardTexture(int w, int h) : w(w), h(h), stride(w*sizeof(PixelType)), fw(w-1), fh(h-1), buff(w*h) { memset(buff.data(),0,sizeof(PixelType) * buff.size()); } int getWidth() const { return w; } float getWidthF() const { return fw; } int getHeight() const { return h; } float getHeightF() const { return fw; } int getStride() const { return stride; } // Pixel manipulation void getPixel(const glm::ivec2& pos, glm::vec4& colourKernel) const { const PixelType& pix = buff[((pos.y % h) * w) + (pos.x % w)]; pix.fillKernel(colourKernel); } virtual void setPixel(const glm::ivec2& pos, const glm::vec4& colourKernel){ PixelType& pix = buff[((pos.y % h) * w) + (pos.x % w)]; pix.fromKernel(colourKernel); } void* getRawPixels() { return buff.data(); } const void* getRawPixels() const { return buff.data(); } }; #endif // STANDARDTEXTURE_HPP But we're still not quite ready to load images using stb. We'll need a few more helper functions.
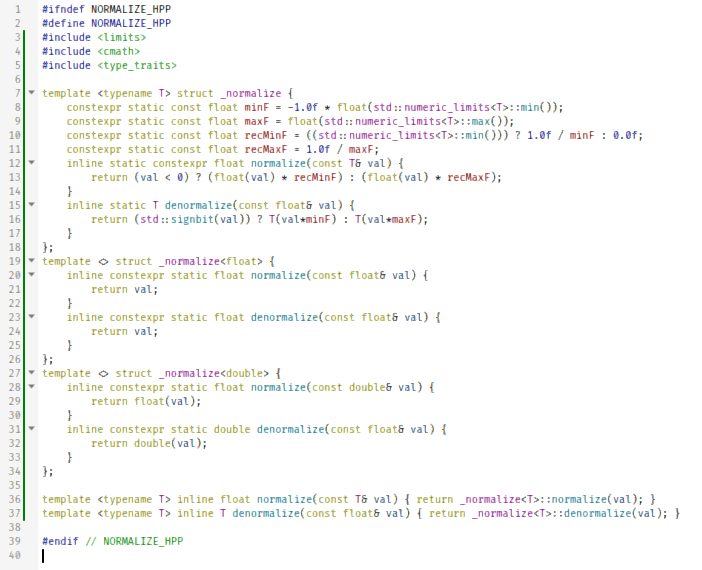
#ifndef NORMALIZE_HPP #define NORMALIZE_HPP #include <limits> #include <cmath> #include <type_traits> template <typename T> struct _normalize { constexpr static const float minF = -1.0f * float(std::numeric_limits<T>::min()); constexpr static const float maxF = float(std::numeric_limits<T>::max()); constexpr static const float recMinF = ((std::numeric_limits<T>::min())) ? 1.0f / minF : 0.0f; constexpr static const float recMaxF = 1.0f / maxF; inline static constexpr float normalize(const T& val) { return (val < 0) ? (float(val) * recMinF) : (float(val) * recMaxF); } inline static T denormalize(const float& val) { return (std::signbit(val)) ? T(val*minF) : T(val*maxF); } }; template <> struct _normalize<float> { inline constexpr static float normalize(const float& val) { return val; } inline constexpr static float denormalize(const float& val) { return val; } }; template <> struct _normalize<double> { inline constexpr static float normalize(const double& val) { return float(val); } inline constexpr static double denormalize(const float& val) { return double(val); } }; template <typename T> inline float normalize(const T& val) { return _normalize<T>::normalize(val); } template <typename T> inline T denormalize(const float& val) { return _normalize<T>::denormalize(val); } #endif // NORMALIZE_HPP With this set of functions, we can easily normalize integers into floating-point values and vice versa. Think of it as a way of mapping the `[0,255]` range to `[0,1]` and vice versa, or `[-128,127]` range into `[-1,1]` and vice versa. Why is this necessary? Well, this will allow us to template pixel formats.

template <typename T> struct StdPixelGreyscale { T val; inline void fillKernel(glm::vec4& colourKernel) const { const float norm = normalize(val); colourKernel.r = norm; colourKernel.g = norm; colourKernel.b = norm; colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { val = denormalize<T>( (0.2989f * colourKernel.r) + (0.5870f * colourKernel.g) + ( 0.1140f * colourKernel.b) ); } }; template <typename T> struct StdPixelRgb { T r,g,b; inline void fillKernel(glm::vec4& colourKernel) const { colourKernel.r = normalize(r); colourKernel.g = normalize(g); colourKernel.b = normalize(b); colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { r = denormalize<T>(colourKernel.r); g = denormalize<T>(colourKernel.g); b = denormalize<T>(colourKernel.b); } }; template <typename T> struct StdPixelRgba { T r,g,b,a; inline void fillKernel(glm::vec4& colourKernel) const { colourKernel.r = normalize(r); colourKernel.g = normalize(g); colourKernel.b = normalize(b); colourKernel.a = normalize(a); } inline void fromKernel(const glm::vec4& colourKernel) { r = denormalize<T>(colourKernel.r); g = denormalize<T>(colourKernel.g); b = denormalize<T>(colourKernel.b); a = denormalize<T>(colourKernel.a); } }; typedef StdPixelGreyscale<uint8_t> PixelGrey8; typedef StandardTexture<PixelGrey8> TextureGrey8; typedef StdPixelGreyscale<uint16_t> PixelGrey16; typedef StandardTexture<PixelGrey16> TextureGrey16; typedef StdPixelRgb<uint8_t> PixelRgb24; typedef StandardTexture<PixelRgb24> TextureRgb24; typedef StdPixelRgba<uint8_t> PixelRgba32; typedef StandardTexture<PixelRgba32> TextureRgba32; typedef StdPixelRgb<uint16_t> PixelRgb48; typedef StandardTexture<PixelRgb48> TextureRgb48; typedef StdPixelRgba<uint16_t> PixelRgba64; typedef StandardTexture<PixelRgba64> TextureRgba64; This will allow us to easily work with just about any kind of standard texture type, even floating-point ones. And now, we can write a function for loading with stb.
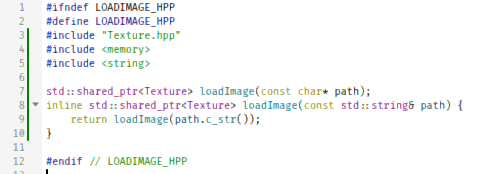
#ifndef LOADIMAGE_HPP #define LOADIMAGE_HPP #include "Texture.hpp" #include <memory> #include <string> std::shared_ptr<Texture> loadImage(const char* path); inline std::shared_ptr<Texture> loadImage(const std::string& path) { return loadImage(path.c_str()); } #endif // LOADIMAGE_HPP
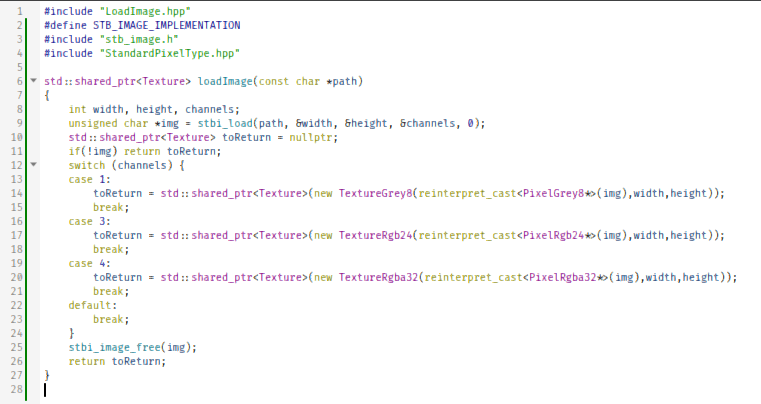
#include "LoadImage.hpp" #define STB_IMAGE_IMPLEMENTATION #include "stb_image.h" #include "StandardPixelType.hpp" std::shared_ptr<Texture> loadImage(const char *path) { int width, height, channels; unsigned char *img = stbi_load(path, &width, &height, &channels, 0); std::shared_ptr<Texture> toReturn = nullptr; if(!img) return toReturn; switch (channels) { case 1: toReturn = std::shared_ptr<Texture>(new TextureGrey8(reinterpret_cast<PixelGrey8*>(img),width,height)); break; case 3: toReturn = std::shared_ptr<Texture>(new TextureRgb24(reinterpret_cast<PixelRgb24*>(img),width,height)); break; case 4: toReturn = std::shared_ptr<Texture>(new TextureRgba32(reinterpret_cast<PixelRgba32*>(img),width,height)); break; default: break; } stbi_image_free(img); return toReturn; } An image having a single channel means it being greyscale. If it has 3 channels, it's 24-bit RGB, and if it has 4 channels, it's 32-bit RGBA. Now, more experienced C++ programmers might want to gouge out their eyes at the sight of my usage of **reinterpret_cast**, but we know exactly what we're doing - unless STB lies to us, we already know how big will each struct be. This is why the polymorphism of C++ is such a useful features. Look at how easily we can abstract the three different types of texture formats! However, to display our little texture, we'll need a new pipeline with new inputs.
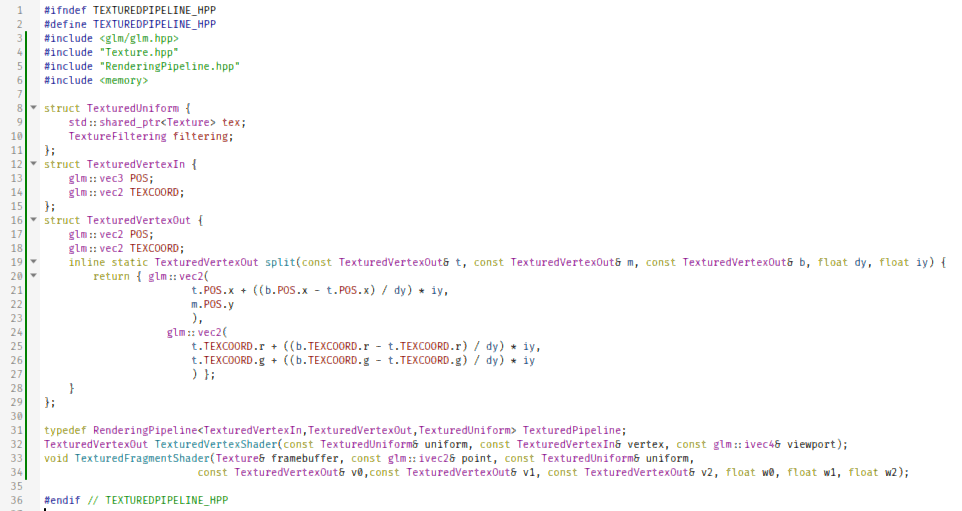
#ifndef TEXTUREDPIPELINE_HPP #define TEXTUREDPIPELINE_HPP #include <glm/glm.hpp> #include "Texture.hpp" #include "RenderingPipeline.hpp" #include <memory> struct TexturedUniform { std::shared_ptr<Texture> tex; TextureFiltering filtering; }; struct TexturedVertexIn { glm::vec3 POS; glm::vec2 TEXCOORD; }; struct TexturedVertexOut { glm::vec2 POS; glm::vec2 TEXCOORD; inline static TexturedVertexOut split(const TexturedVertexOut& t, const TexturedVertexOut& m, const TexturedVertexOut& b, float dy, float iy) { return { glm::vec2( t.POS.x + ((b.POS.x - t.POS.x) / dy) * iy, m.POS.y ), glm::vec2( t.TEXCOORD.r + ((b.TEXCOORD.r - t.TEXCOORD.r) / dy) * iy, t.TEXCOORD.g + ((b.TEXCOORD.g - t.TEXCOORD.g) / dy) * iy ) }; } }; typedef RenderingPipeline<TexturedVertexIn,TexturedVertexOut,TexturedUniform> TexturedPipeline; TexturedVertexOut TexturedVertexShader(const TexturedUniform& uniform, const TexturedVertexIn& vertex, const glm::ivec4& viewport); void TexturedFragmentShader(Texture& framebuffer, const glm::ivec2& point, const TexturedUniform& uniform, const TexturedVertexOut& v0,const TexturedVertexOut& v1, const TexturedVertexOut& v2, float w0, float w1, float w2); #endif // TEXTUREDPIPELINE_HPP
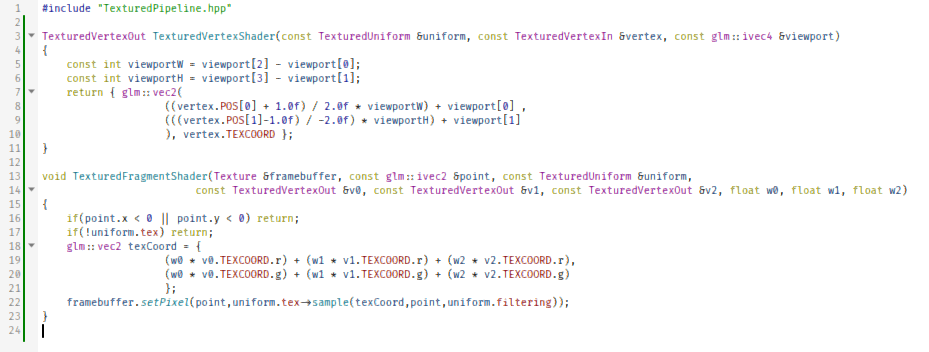
#include "TexturedPipeline.hpp" TexturedVertexOut TexturedVertexShader(const TexturedUniform &uniform, const TexturedVertexIn &vertex, const glm::ivec4 &viewport) { const int viewportW = viewport[2] - viewport[0]; const int viewportH = viewport[3] - viewport[1]; return { glm::vec2( ((vertex.POS[0] + 1.0f) / 2.0f * viewportW) + viewport[0] , (((vertex.POS[1]-1.0f) / -2.0f) * viewportH) + viewport[1] ), vertex.TEXCOORD }; } void TexturedFragmentShader(Texture &framebuffer, const glm::ivec2 &point, const TexturedUniform &uniform, const TexturedVertexOut &v0, const TexturedVertexOut &v1, const TexturedVertexOut &v2, float w0, float w1, float w2) { if(point.x < 0 || point.y < 0) return; if(!uniform.tex) return; glm::vec2 texCoord = { (w0 * v0.TEXCOORD.r) + (w1 * v1.TEXCOORD.r) + (w2 * v2.TEXCOORD.r), (w0 * v0.TEXCOORD.g) + (w1 * v1.TEXCOORD.g) + (w2 * v2.TEXCOORD.g) }; framebuffer.setPixel(point,uniform.tex->sample(texCoord,point,uniform.filtering)); } Those who already have some experience with graphics may notice something missing from our pipeline, but those who do - don't spoil it for the rest ;) It's similar to our pre-existing basic pipeline, but our secondary vertex attribute is not a 4-dimensional vector *(RGBA colour)* but instead a 2-dimensional vector *(**UV coordinate**)*. We use this UV coordinate to sample our texture to fill our colour kernel, and then paint the pixel onto the screen. https://en.wikipedia.org/wiki/UV_mapping Once sampling the texture to fill our colour kernel, we could modulate the colour *(e.g. multiplying it with a per-vertex colour)*, but since we're not doing that, I did a shortcut and cut off the intermediate colour kernel. Next, we modify our application class to include this new pipeline.
#include "SoftwareRendererSystem.hpp" #include "LoadImage.hpp" SoftwareRendererSystem::SoftwareRendererSystem(int width, int height) : AppSystem("Software Renderer Demo",0,0,width,height,0), renderer(SDL_CreateRenderer(this->window.get(),0,0),SDL_DestroyRenderer), framebuffer(SDL_CreateTexture(this->renderer.get(), SDL_PIXELFORMAT_RGBA8888, SDL_TEXTUREACCESS_STREAMING, width,height),SDL_DestroyTexture), renderBuffer(width,height) { pipeline.viewport[0] = 0; pipeline.viewport[1] = 0; pipeline.viewport[2] = width; pipeline.viewport[3] = height; pipeline.vert = TexturedVertexShader; pipeline.frag = TexturedFragmentShader; pipeline.framebuffer = &renderBuffer; pipeline.uniform = { nullptr, NEAREST_NEIGHBOUR }; pipeline.uniform.tex = loadImage("brickwall.png"); } void SoftwareRendererSystem::processEvent(const SDL_Event &ev, bool &causesExit) { switch(ev.type) { case SDL_QUIT: causesExit = true; break; default: break; } } void SoftwareRendererSystem::updateLogic() { } static const std::vector<TexturedVertexIn> vertices = { { glm::vec3(-0.8f, 0.8f,0.f), glm::vec2(0.0f, 0.0f) }, // 0 { glm::vec3(-0.8f, -0.8f,0.f), glm::vec2(0.0f, 1.0f) }, // 1 { glm::vec3(0.8f, 0.8f,0.0f), glm::vec2(1.0f, 0.0f) }, // 2 { glm::vec3(0.8f, -0.8f,0.0f), glm::vec2(1.0f, 1.0f) } // 3 }; static const std::vector<unsigned> indices = { 0, 1, 2, 1, 2, 3 }; void SoftwareRendererSystem::render() { pipeline.renderTriangles(vertices.data(),indices.data(), indices.size() ); SDL_UpdateTexture(framebuffer.get(), nullptr, renderBuffer.getRawPixels(), renderBuffer.getStride() ); SDL_RenderCopy(renderer.get(), framebuffer.get(), nullptr, nullptr); SDL_RenderPresent(renderer.get()); SDL_Delay(16); } And voila, we got a textured rectangle!
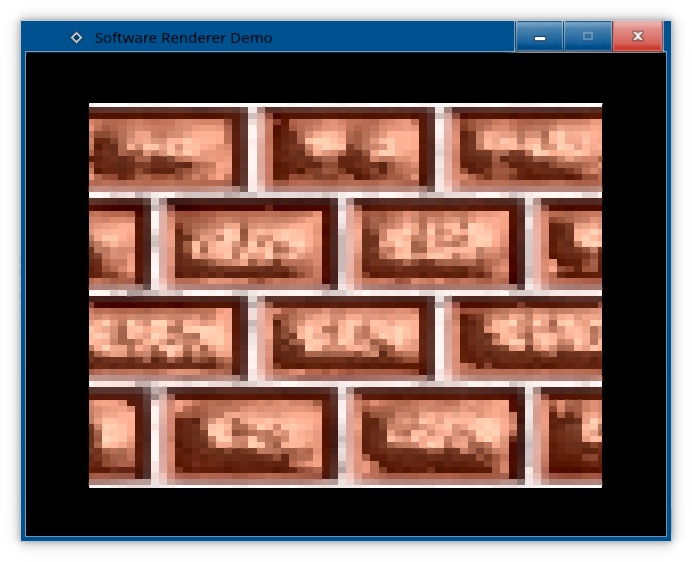
But it looks rather pixelated, doesn't it? Perhaps it's high time to implement the other two texture filtering methods. Texture Filtering Bilinear Filtering As stated previously, bilinear filtering is implement by taking the weighted averages of our pixels.
#include "Texture.hpp" #include <cmath> void Texture::sample(const glm::vec2 &pos, const glm::ivec2 &screenpos, TextureFiltering filteringType, glm::vec4 &colourKernel) const { switch (filteringType) { case NEAREST_NEIGHBOUR: getPixel(glm::ivec2( int( std::round(pos.x*getWidthF())) % getWidth() , int(std::round(pos.y * getHeightF())) % getHeight() ), colourKernel); break; case DITHERED: // To be implemented later break; case BILINEAR: { const int w = getWidth(); const int h = getHeight(); const glm::vec2 tmp = glm::vec2(pos.x * getWidthF(),pos.y * getHeightF() ); const glm::vec2 coordEdgeTopLeft( std::floor(tmp[0]), std::floor(tmp[1]) ); const glm::vec2 coordEdgeTopRight( std::ceil(tmp[0]), std::floor(tmp[1]) ); const glm::vec2 coordEdgeBottomLeft( std::floor(tmp[0]), std::ceil(tmp[1]) ); const glm::vec2 coordEdgeBottomRight( std::ceil(tmp[0]), std::ceil(tmp[1]) ); const glm::vec2 weight = tmp - coordEdgeTopLeft; glm::vec4 colourTopLeft, colourTopRight, colourBottomLeft, colourBottomRight; getPixel(glm::ivec2( int(coordEdgeTopLeft[0]) % w,int(coordEdgeTopLeft[1]) % h ),colourTopLeft ); getPixel(glm::ivec2( int(coordEdgeTopRight[0]) % w,int(coordEdgeTopRight[1]) % h ),colourTopRight ); getPixel(glm::ivec2( int(coordEdgeBottomLeft[0]) % w,int(coordEdgeBottomLeft[1]) % h ),colourBottomLeft ); getPixel(glm::ivec2( int(coordEdgeBottomRight[0]) % w,int(coordEdgeBottomRight[1]) % h ),colourBottomRight ); colourTopLeft *= ((1.0f-weight[0]) * (1.0f-weight[1])); colourTopRight *= (weight[0] * (1.0f-weight[1])); colourBottomLeft *= ((1.0f-weight[0]) * weight[1]); colourBottomRight *= (weight[0] * weight[1]); colourKernel = colourTopLeft + colourTopRight + colourBottomLeft + colourBottomRight; break; } default: break; } } And, we got bilinear filtering!
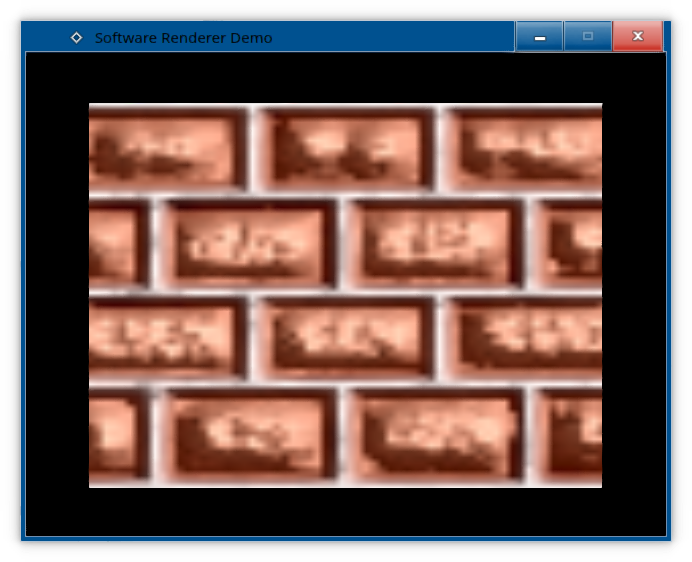
But I bet you are curious about what kind of mathematical black magic did we have to perform to do this, so I will try my best to explain. We translate our normalized texture coordinate from `{ [0,1], [0,1] }` to `{ [0,WIDTH], [0,HEIGHT] }`. In the case of this 64x64 texture, that means translating `{ [0,1], [0,1] }` to `{ [0,64], [0,64] }`. We calculate the four edges by using different types of rounding. To get the top left edge, we need to round down both coordinates. To get the top-left corner's coordinate, we round down both of the aforementioned coordinates. To get the top-right corner's coordinate, we round up the X-coordinate, but round down the Y-coordinate. To get the bottom-left coordinate, we round down the X-coordinate, but round up the Y-coordinate. To get the bottom-right coordinate, we round down up both coordinates. We get a normalized two-dimensional weight coordinate by subtracting the top-left coordinate from the aforementioned temporary coordinate. The end result is a two-dimensional vector, with both numbers between 0 and 1. We declare four colour kernels and fill them with colours of each corner. We multiply the four colour kernels with the appropriate weights. For the top-left one, that is going to be `{ 1-weightX, 1-weightY }`. For the top-right one, that is going to be `{ weightX, 1-weightY }`. For the bottom-left one, that is going to be `{ 1-weightX, weightY }`. For the bottom-right one, that is going to be `{ weightX, weightY }`. We add all the colour kernels together, which results in a weighted average of them, given how we multiplied them with the weights before. Congratulations, you just bilinearly sampled a pixel colour. Needless to say, this will be slow as hell, but hey - beauty requires sacrifices. Among others, Outcast used a software renderer with bilinear filtering. https://www.youtube.com/watch?v=D1gru-m1fqg Dithered texture filtering True bilinear filtering is slow, and best left out of software renderers altogether. But if you really want to avoid the jagged sharp pixels, we can still fake bilinear filtering with a simple ordered dither, as was done in Unreal. https://www.flipcode.com/archives/Texturing_As_In_Unreal.shtml
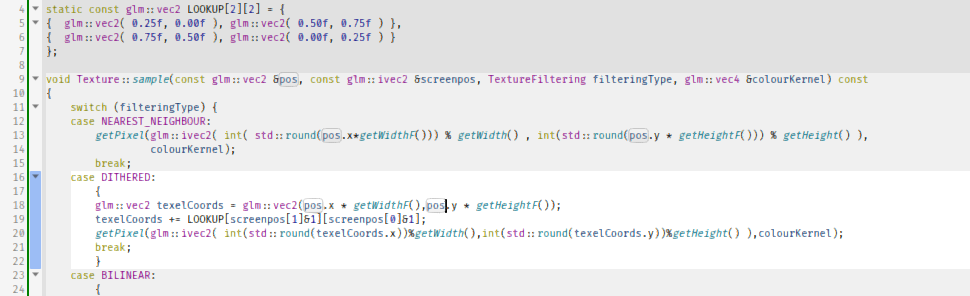
static const glm::vec2 LOOKUP[2][2] = { { glm::vec2( 0.25f, 0.00f ), glm::vec2( 0.50f, 0.75f ) }, { glm::vec2( 0.75f, 0.50f ), glm::vec2( 0.00f, 0.25f ) } }; void Texture::sample(const glm::vec2 &pos, const glm::ivec2 &screenpos, TextureFiltering filteringType, glm::vec4 &colourKernel) const { switch (filteringType) { case NEAREST_NEIGHBOUR: getPixel(glm::ivec2( int( std::round(pos.x*getWidthF())) % getWidth() , int(std::round(pos.y * getHeightF())) % getHeight() ), colourKernel); break; case DITHERED: { glm::vec2 texelCoords = glm::vec2(pos.x * getWidthF(),pos.y * getHeightF()); texelCoords += LOOKUP[screenpos[1]&1][screenpos[0]&1]; getPixel(glm::ivec2( int(std::round(texelCoords.x))%getWidth(),int(std::round(texelCoords.y))%getHeight() ),colourKernel); break; } case BILINEAR: { // We already discussed you, bilinear... } default: break; } } And the end result is...
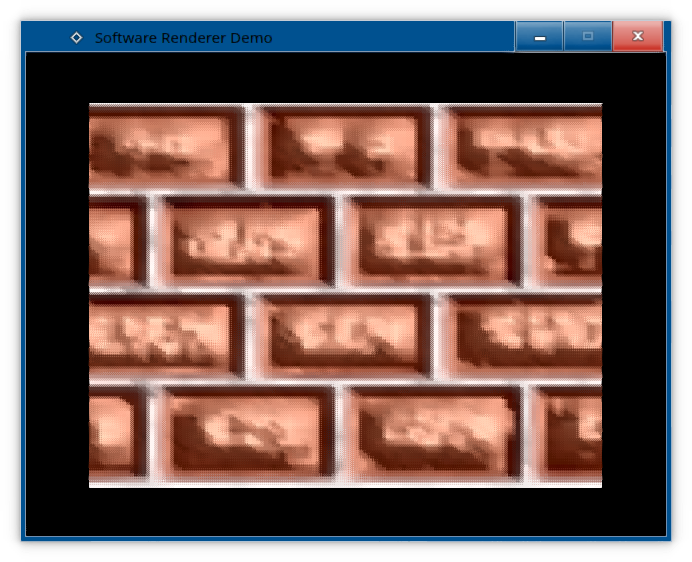
Virtually indistinguishable from the regular bilinear filter, save for the checkerboard pattern that only the most observant will notice. But hey, it comes with almost zero performance impact! But these rectangles are getting boring, we should render something more exciting... In the next episode, we'll get into more exciting things: Z-Buffers, cameras, and more complex shapes! But before that, I'd like to take a little detour on dithering... Dithering colours Most of the times, when you hear the word *"dithering"*, it refers to dithering performed on a colour kernel, rather than texture coordinates. Now, why would you want to dither colours? Well, let's just, what if you need to resort to a lower colour depth, say 16-bit colour instead of 24-bit colour?

struct PixelRgb565 { uint16_t rgb; static constexpr const float i4r = 1.0f / 15.0f; static constexpr const float i5r = 1.0f / 31.0f; static constexpr const float i6r = 1.0f / 63.0f; static constexpr const float reciprocal = 1.0f / 255.0f; inline void fillKernel(glm::vec4& colourKernel) const { const uint16_t r = (rgb & 0xF800) >> 11; const uint16_t g = (rgb & 0x07E0) >> 5; const uint16_t b = (rgb & 0x001F); colourKernel.r = float(r) * i5r; colourKernel.g = float(g) * i6r; colourKernel.b = float(b) * i5r; colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { const uint16_t r = uint16_t(colourKernel.r * 31.0f); const uint16_t g = uint16_t(colourKernel.g * 63.0f); const uint16_t b = uint16_t(colourKernel.b * 31.0f); rgb = ((r << 11) | (g << 5) | b); } }; typedef StandardTexture<PixelRgb565> TextureRgb565; If we just modify the renderer's framebuffer to this type, we're going to be met with a nasty surprise:
Look at that terrible colour-banding! It's horrible! We need to do something about it! And the solution is dithering. Ordered dithering. https://en.wikipedia.org/wiki/Ordered_dithering

#ifndef DITHER_HPP #define DITHER_HPP #include <cstddef> #include <algorithm> template <typename T, T maximum> struct OrderedDither { static constexpr const float MAX = ((float(maximum)+1.0f) * 8.0f) - 1.0f; static constexpr const float MAX_RECIPROCAL = 1.0f/float(MAX); static constexpr const float LookupTable[4][4] = { {0.0f * MAX_RECIPROCAL, 8.0f * MAX_RECIPROCAL, -2.0f * MAX_RECIPROCAL, 10.0f * MAX_RECIPROCAL}, {12.0f * MAX_RECIPROCAL, -4.0f * MAX_RECIPROCAL, 14.0f * MAX_RECIPROCAL, -6.0f * MAX_RECIPROCAL}, {-3.0f * MAX_RECIPROCAL, 11.0f * MAX_RECIPROCAL, -1.0f * MAX_RECIPROCAL, 9.0f * MAX_RECIPROCAL}, {15.0f * MAX_RECIPROCAL, -7.0f * MAX_RECIPROCAL, 13.0f * MAX_RECIPROCAL, -5.0f * MAX_RECIPROCAL} }; static constexpr float ditherUp(float value, const glm::ivec2& coords) { return std::clamp(value + LookupTable[coords.y%4][coords.x%4],0.0f,1.0f); } static constexpr float ditherDown(float value, const glm::ivec2& coords) { return std::clamp(value - LookupTable[coords.y%4][coords.x%4],0.0f,1.0f); } }; #endif // DITHER_HPP Next, we update our pixel and texture classes to accomodate for this new functionality.

struct PixelRgb565 { uint16_t rgb; typedef OrderedDither<uint8_t,31> Dither5; typedef OrderedDither<uint8_t,63> Dither6; static constexpr const float i5r = 1.0f / 31.0f; static constexpr const float i6r = 1.0f / 63.0f; static constexpr const float reciprocal = 1.0f / 255.0f; inline void fillKernel(glm::vec4& colourKernel) const { const uint16_t r = (rgb & 0xF800) >> 11; const uint16_t g = (rgb & 0x07E0) >> 5; const uint16_t b = (rgb & 0x001F); colourKernel.r = float(r) * i5r; colourKernel.g = float(g) * i6r; colourKernel.b = float(b) * i5r; colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { const uint16_t r = uint16_t(colourKernel.r * 31.0f); const uint16_t g = uint16_t(colourKernel.g * 63.0f); const uint16_t b = uint16_t(colourKernel.b * 31.0f); rgb = ((r << 11) | (g << 5) | b); } inline void fromKernelDithered(const glm::vec4& colourKernel, const glm::ivec2& screencoord) { const uint16_t r = uint16_t(Dither5::ditherDown(colourKernel.r,screencoord) * 31.0f); const uint16_t g = uint16_t(Dither6::ditherDown(colourKernel.g,screencoord) * 63.0f); const uint16_t b = uint16_t(Dither5::ditherDown(colourKernel.b,screencoord) * 31.0f); rgb = ((r << 11) | (g << 5) | b); } }; typedef StandardTexture<PixelRgb565> TextureRgb565;
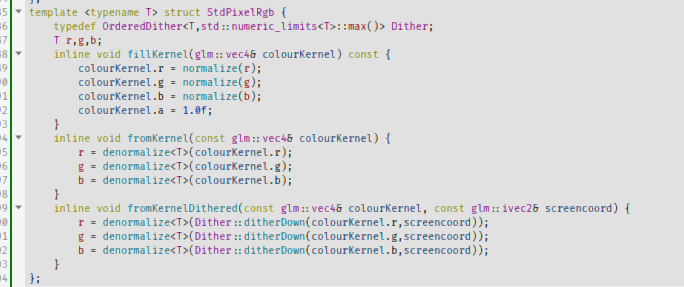
template <typename T> struct StdPixelRgb { typedef OrderedDither<T,std::numeric_limits<T>::max()> Dither; T r,g,b; inline void fillKernel(glm::vec4& colourKernel) const { colourKernel.r = normalize(r); colourKernel.g = normalize(g); colourKernel.b = normalize(b); colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { r = denormalize<T>(colourKernel.r); g = denormalize<T>(colourKernel.g); b = denormalize<T>(colourKernel.b); } inline void fromKernelDithered(const glm::vec4& colourKernel, const glm::ivec2& screencoord) { r = denormalize<T>(Dither::ditherDown(colourKernel.r,screencoord)); g = denormalize<T>(Dither::ditherDown(colourKernel.g,screencoord)); b = denormalize<T>(Dither::ditherDown(colourKernel.b,screencoord)); } };
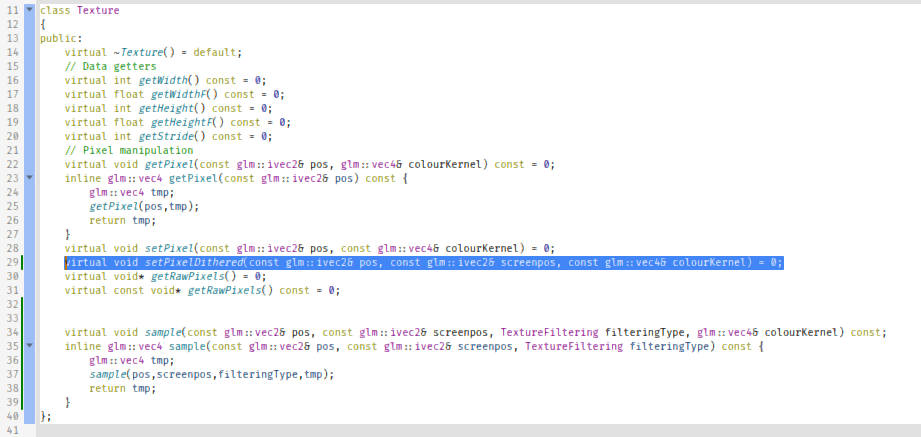
class Texture { public: virtual ~Texture() = default; // Data getters virtual int getWidth() const = 0; virtual float getWidthF() const = 0; virtual int getHeight() const = 0; virtual float getHeightF() const = 0; virtual int getStride() const = 0; // Pixel manipulation virtual void getPixel(const glm::ivec2& pos, glm::vec4& colourKernel) const = 0; inline glm::vec4 getPixel(const glm::ivec2& pos) const { glm::vec4 tmp; getPixel(pos,tmp); return tmp; } virtual void setPixel(const glm::ivec2& pos, const glm::vec4& colourKernel) = 0; virtual void setPixelDithered(const glm::ivec2& pos, const glm::ivec2& screenpos, const glm::vec4& colourKernel) = 0; virtual void* getRawPixels() = 0; virtual const void* getRawPixels() const = 0; virtual void sample(const glm::vec2& pos, const glm::ivec2& screenpos, TextureFiltering filteringType, glm::vec4& colourKernel) const; inline glm::vec4 sample(const glm::vec2& pos, const glm::ivec2& screenpos, TextureFiltering filteringType) const { glm::vec4 tmp; sample(pos,screenpos,filteringType,tmp); return tmp; } }; And we also update our pipelines to use **setPixelDithered** instead of **setPixel** too. And after that, look at the results!
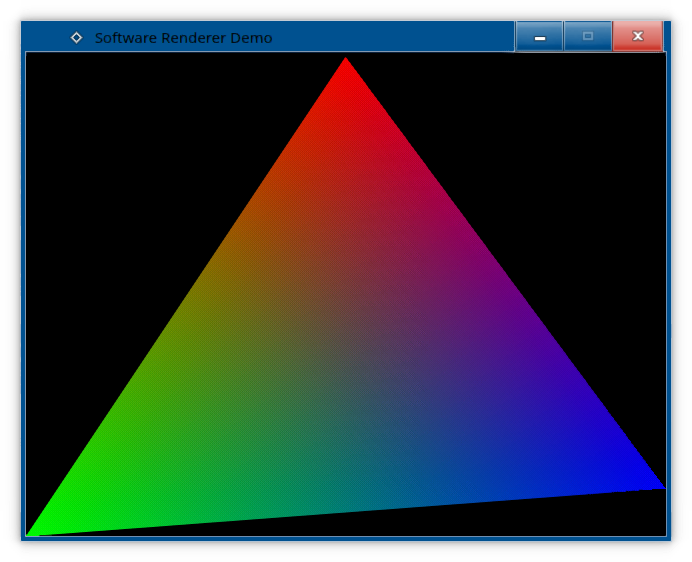
Smooth as butter, not a single banding artifact present. But why even stop at 16-bit colour, if we can go even lower? Let's do 8-bit RGB332 then!

struct PixelRgb332 { uint8_t rgb; typedef OrderedDither<uint8_t,3> Dither2; typedef OrderedDither<uint8_t,7> Dither3; static constexpr const float i2r = 1.0f / 3.0f; static constexpr const float i3r = 1.0f / 7.0f; inline void fillKernel(glm::vec4& colourKernel) const { const uint8_t r = (rgb & 0xE0) >> 5; const uint8_t g = (rgb & 0x1C) >> 2; const uint8_t b = (rgb & 0x03); colourKernel.r = float(r) * i3r; colourKernel.g = float(g) * i3r; colourKernel.b = float(b) * i2r; colourKernel.a = 1.0f; } inline void fromKernel(const glm::vec4& colourKernel) { const uint16_t r = uint16_t(colourKernel.r * 7.0f); const uint16_t g = uint16_t(colourKernel.g * 7.0f); const uint16_t b = uint16_t(colourKernel.b * 3.0f); rgb = ((r << 5) | (g << 2) | b); } inline void fromKernelDithered(const glm::vec4& colourKernel, const glm::ivec2& screencoord) { const uint16_t r = uint16_t(Dither3::ditherDown(colourKernel.r,screencoord) * 7.0f); const uint16_t g = uint16_t(Dither3::ditherDown(colourKernel.g,screencoord) * 7.0f); const uint16_t b = uint16_t(Dither2::ditherDown(colourKernel.b,screencoord) * 3.0f); rgb = ((r << 5) | (g << 2) | b); } }; typedef StandardTexture<PixelRgb332> TextureRgb332; First, without dither:
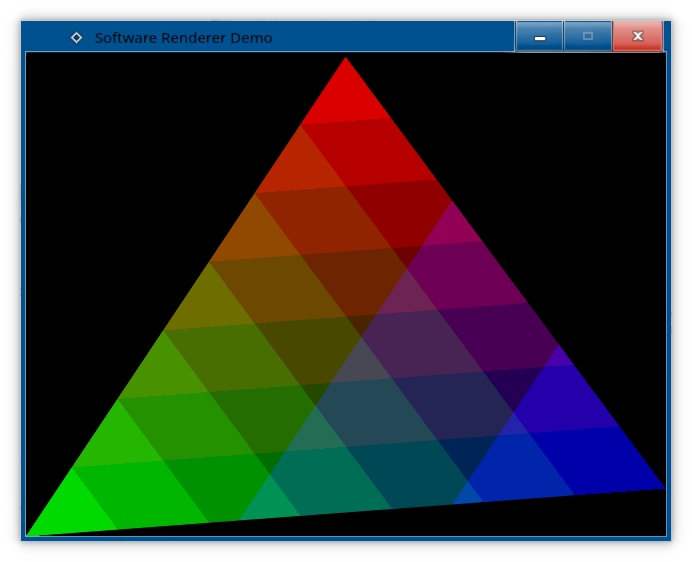
Okay, now with dither:
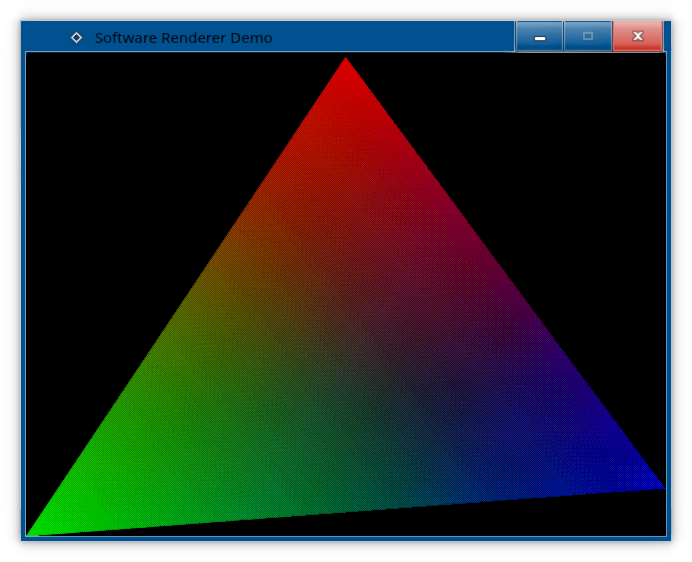
So yeah, now we can also render in 16-bit *(64k colours)* and 8-bit *(256 colours)* framebuffers, if we want. But enough of this detour. In the next episode, we'll get serious with more complex shapes, Z-Buffers and cameras! Until then, as always, the code within this episode is uploaded onto Github. https://github.com/Metalhead33/SoftwareRendererTutorial
No comments yet