
Churn is a widely used KPI, focused in finding the rate at which customers stop doing business with an entity. It represents the percentage of service subscribers who discontinue their subscriptions within a given time period. For each industry, Companies might experience different rates, which it essential to track, as long as it may affect the Annual Recurrent Revenue (ARR), Customer Acquisition Cost (CAC) and other relevant KPIs.


We will build from scratch a simple Machine Learning model, with the help of LazyPredict, to predict potential Churn in Customers. The construction is divided into three categories - that could be extended to extra steps, if extra information is available:
Data Visualization;
Data Preparation
Machine Learning / Prediction.
Here we go 👇
First, we import the libraries for Data Cleaning/Visualization, LazyPredict and SKLearn.
## Libraries for data cleaning/visualization
import pandas as pd
pd.set_option("display.max_columns", 100)
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
## Lazy predict for an initial guide
import lazypredict
from lazypredict.Supervised import LazyClassifier
## Import sklearn libraries
from sklearn.metrics import roc_auc_score, accuracy_score, f1_score, confusion_matrix, classification_report
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import RidgeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.svm import LinearSVCThe dataset used in this article is originally from IBM (“Build a customer churn predictor using Watson Studio and Jupyter Notebooks”). It is available at GitHub, as shown below. Now, lets take a further look at it:
## Initial Dataframe
df = pd.read_csv('https://raw.githubusercontent.com/carlosfab/dsnp2/master/datasets/WA_Fn-UseC_-Telco-Customer-Churn.csv')
## Main infos about shape and nulls
print(f"Total lines: {df.shape[0]}")
print(f"Total columns: {df.shape[1]}\n")
## Print the dataframe
df.head(10)
## By passing the show_counts as true, we visualize that there are not null values
df.info(show_counts=True)Initial view from the raw DataFrame:
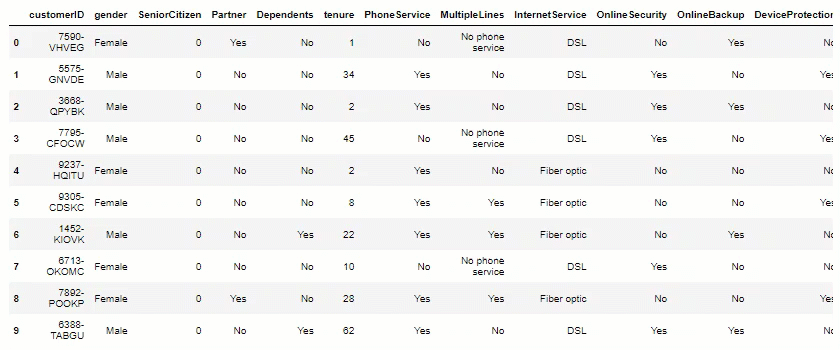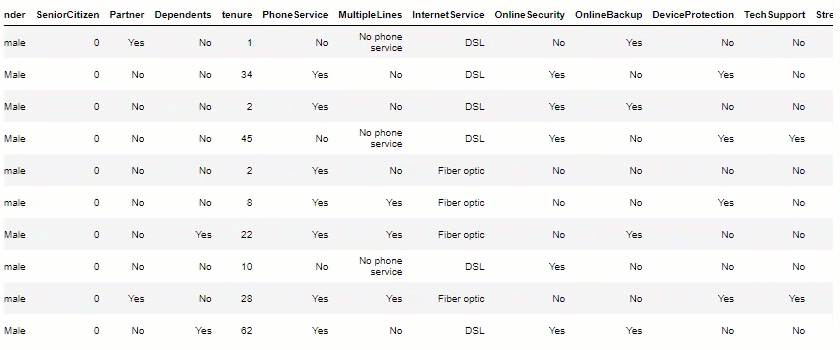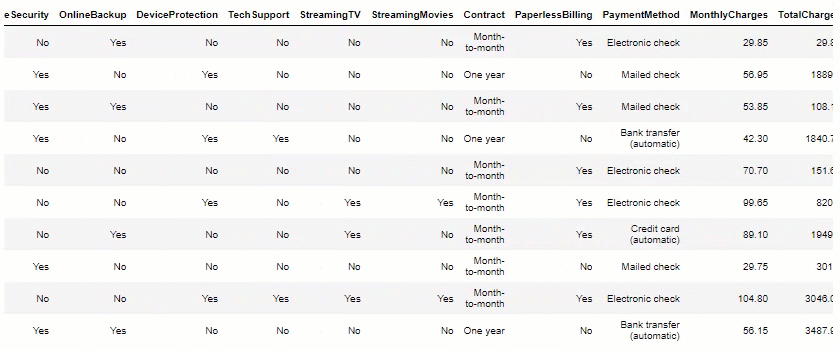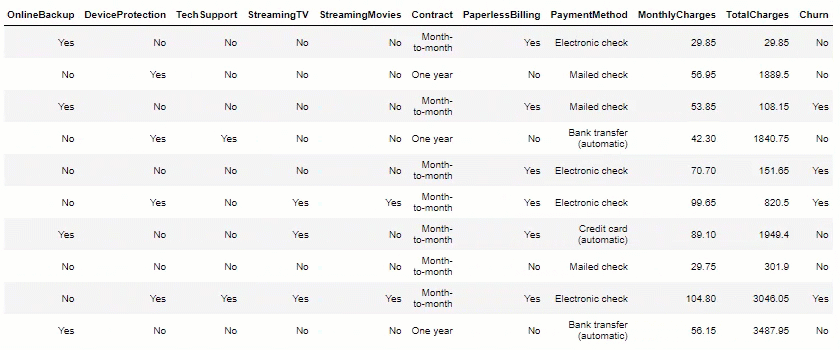
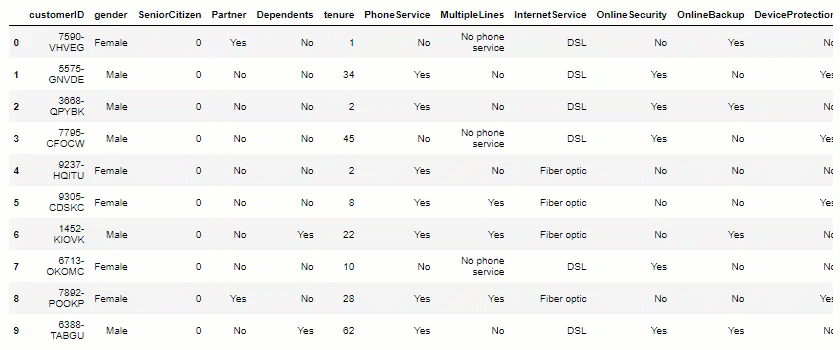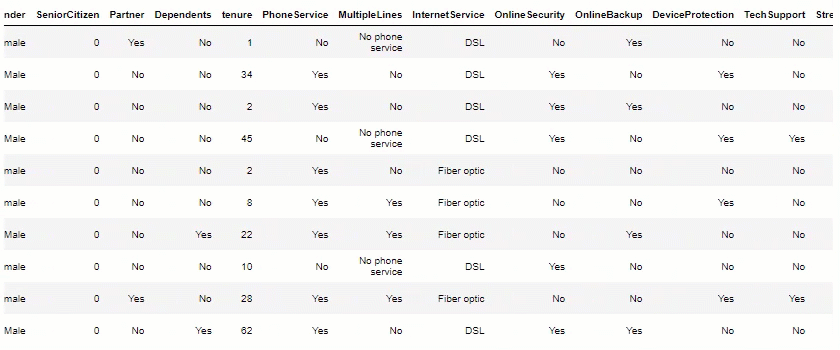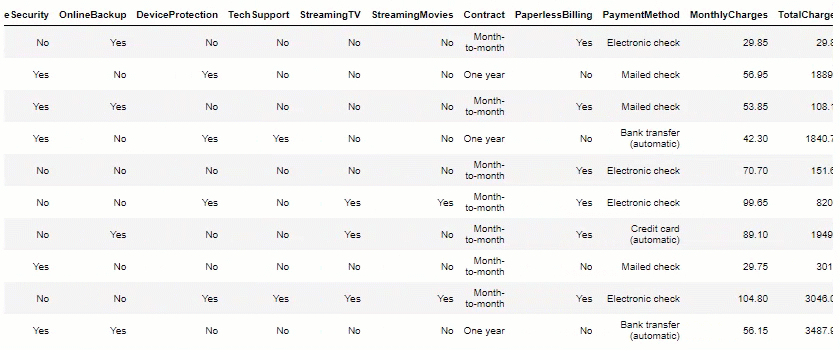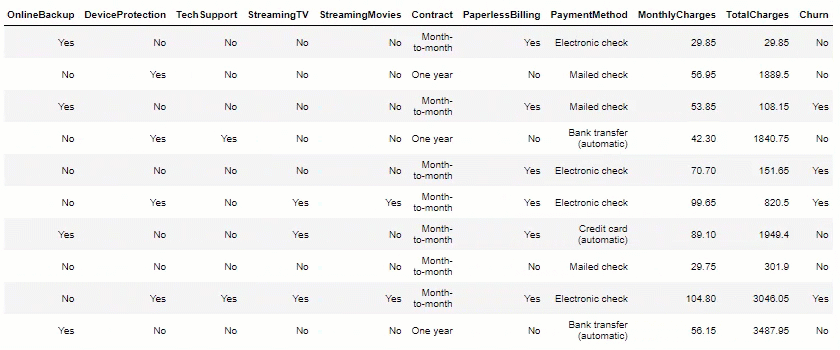
Data Visualization: Now, let’s plot some views, to help us measure potential insights.


At first sight, there is two potential insights from this database: it seems to have not a direct correlation between multiple lines from Customers and the Churn Rate is higher in a Month-to-Month contract. Well, what about the prices, does it affect the Churn?


By splitting our Churn into gender and visualizing in the graph above, we do not expect a huge difference to be measured by gender, but we do infer a higher churn meanwhile keeping a low MonthlyCharge. For a final visualization, we plot the Tenure, which represents the amount of time the Customer remains adherent to the Company. As expected, there is a inverse correlation: the majority of Customers with Churn happens in the first periods.
For this visualization, Churn is 1 (Orange) or 0 (Green).


Data Preparation: Now we need to prepare the data, by generating some dummies for categorical variables, look for potential errors and convert the datatypes from the DataFrame so far.
## We need to drop the customer ID, a non relevant info (but storing it in a new dataframe)
df_id = df['customerID']
df.drop(['customerID'], axis=1, inplace=True)
## For the models to work, we need to set the dependent variable as a dummy, with a lambda function
df['Churn'] = df['Churn'].apply(lambda x: 0 if x == 'No' else 1 )
## TotalCharges is a numeric column. As such, we need to convert it.
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce')
## Now, we grab the index of all erros, so we can further investigate
erros_total_charges = list(df['TotalCharges'].loc[df['TotalCharges'].isnull()].index)
## Now we plot the errors, and it seems to match the lines where tenure is null
(df.iloc[erros_total_charges] == df.loc[df['tenure'] == 0])
## So, for this situation, we plot the monthly charges to each respective line
df['TotalCharges'].iloc[erros_total_charges] = df['MonthlyCharges'].iloc[erros_total_charges]
## Now we select all the columns which stands as objects in a list, so we can convert to a dummy
object_columns = []
for i in df.select_dtypes(include=['object']).columns:
if i == 'Churn':
pass
else:
object_columns.extend([i])We’re almost there! Now let’s finish this and create our dummies. For this article, i’m using the function pd.get_dummies from Pandas.
## Now we are ready to convert
df = pd.get_dummies(df, columns=object_columns)
## At this step, we have every column to be a number. So, we convert everything to float (except churn column)
for i in df.columns:
try:
df[i].astype(float)
except:
if i == 'Churn':
passNow we have everything ready to begin the Machine Learning with the help of LazyPredict, which helps to build a lot of basic models without much code and helps understand which models works better without any parameter tuning.
As every ML problem, we must separate our DataFrame in a training and test set. It is crucial to evaluate how well our model performs with data that it has never seen before. For that, SKLearn helps us in a very intuitive way:
## First we set the X and Y (dependent and independent variables)
X = df.drop('Churn', axis=1)
y = df['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y)Easy! Now for the fun part: action! In just three lines, we run 30 machine learning models:
## As a second step, we run the lazy predict, to a enhanced vision about the best models to fit
clf = LazyClassifier(verbose=0, ignore_warnings=True, predictions=True)
models, predictions = clf.fit(X_train, X_test, y_train, y_test)
models.sort_values('Accuracy', ascending=False)
## Now we select the top 4, and run a GridSearch, to tune the hyperparameters
list(models.nlargest(4, columns='Accuracy').reset_index()['Model'])Voilá! Now we have a very nice view from the best algorithms for this situation. For a deeper exercise, we’ll dive into four of them: AdaBoostClassifier, LogisticRegression, LinearSVC and RidgeClassifier.


For that moment, better to take a better look, step-by-step:
## First we instantiate the models
ada = AdaBoostClassifier()
lin_svc = LinearSVC()
ridge = RidgeClassifier()
log_reg = LogisticRegression()
## Now we plot the parameters where grid search might try to find the best match
parameters_ada = {'n_estimators':[10, 50, 250, 1000],
'learning_rate':[0.01, 0.1]}
parameters_lin_svc = {'C':[1, 10, 100, 1000]}
parameters_ridge = {'alpha': [1, 0.1, 0.01, 0.001, 0.0001, 0] ,
"solver": ['svd', 'cholesky', 'lsqr', 'sparse_cg', 'sag', 'saga']}
parameters_log_reg = {'penalty' : ['l1', 'l2', 'elasticnet'],
'multi_class': ['auto', 'ovr', 'multinomial']}
## Now we set the grid search for each model
grid_ada = GridSearchCV(ada, parameters_ada, n_jobs=-1, verbose=0)
grid_lin_svc = GridSearchCV(lin_svc, parameters_lin_svc, n_jobs=-1, verbose=0)
grid_ridge = GridSearchCV(ridge, parameters_ridge, n_jobs=-1, verbose=0)
grid_log_reg = GridSearchCV(log_reg, parameters_log_reg, n_jobs=-1, verbose=0)
## We should fit those parameters into our tests dfs
print('Running GridSearch for Adaboost...')
grid_ada.fit(X_train, y_train)
print('Running GridSearch for LinearSVC...')
grid_lin_svc.fit(X_train, y_train)
print('Running GridSearch for RidgeClassifier...')
grid_ridge.fit(X_train, y_train)
print('Running GridSearch for Logistic Regression...')
grid_log_reg.fit(X_train, y_train)
## At last, we print the best parameters for each model
best_ada = grid_ada.best_params_
print('Best parameters for Adaboost:', best_ada)
best_svc = grid_lin_svc.best_params_
print('Best parameters for Linear SVC:', best_svc)
best_ridge = grid_ridge.best_params_
print('Best parameters for Ridge Classifier:', best_ridge)
best_log = grid_log_reg.best_params_
print('Best parameters for Logistic Regression:', best_log)
## Now we run the best parameters for each model
ada_model = AdaBoostClassifier(n_estimators=best_ada['n_estimators'],
learning_rate=best_ada['learning_rate'])
ada_model.fit(X_train, y_train)
svc_model = LinearSVC(C=best_svc['C'])
svc_model.fit(X_train, y_train)
ridge_model = RidgeClassifier(alpha=best_ridge['alpha'], solver=best_ridge['solver'])
ridge_model.fit(X_train, y_train)
log_model = LogisticRegression(penalty=best_log['penalty'], multi_class=best_log['multi_class'])
log_model.fit(X_train, y_train);First, we instantiate the models into the code, by calling the modules we have imported at the first moment.
Then we plot potential hyperparameters for better improvement of the models.
By setting variables with parameters, we use a technique known as GridSearch, in which we can iterate over several parameters to find the ones with the higher performance. With the help of “Fit” method, it starts running.
Then, we obtain the best parameters which were found after the GridSearch. As long as we need to test it into our model, we might simply pass then as real parameters to each one, by slicing into a dictionary.
No need to rewrite everything again, as it must happen right after.
By the end, we should ask the models to predict against our dependent variable: the churn from the customers.
Let’s go forward!
No need to write all those formulas!
Now we call the method “Predict” along the models, with the help of the metric AUC (instead of Accuracy, which may represent some bias with unbalanced classification problems). From an interpretation standpoint, it is more useful because it shows us how good at ranking predictions your model is.
It tells you what is the probability that a randomly chosen positive instance is ranked higher than a randomly chosen negative instance.
## Predict all the models
ada_predict = ada_model.predict(X_test)
svc_predict = svc_model.predict(X_test)
ridge_predict = ridge_model.predict(X_test)
log_predict = log_model.predict(X_test)
## Grab the best AUC Score
auc_score = {'Adaboost': roc_auc_score(y_test, ada_predict),
'Linear SVC': roc_auc_score(y_test, svc_predict),
'Ridge Classifier': roc_auc_score(y_test, ridge_predict),
'Logistic Regression': roc_auc_score(y_test, log_predict)}
## Obtain the highest value in the auc_score dictionary
best = max(auc_score.items(), key = lambda x: x[1])
print(f'The best performance model is {best[0]}, with an AUC Score of {best[1]}!')Finally, we reach to the end, and the winner is…
The best performance model is Adaboost, with an AUC Score of 0.74!We can plot the confusion matrix from AdaBoost, for a better review over the ratings, such as an Accuracy of 0.81:
precision recall f1-score support
0 0.85 0.91 0.88 1283
1 0.70 0.56 0.62 478
accuracy 0.81 1761
macro avg 0.77 0.74 0.75 1761
weighted avg 0.81 0.78 0.81 1761There is still room for improvement, with the of XGBoost, a higher amount of data or some feature engineering. That’s it for now!